Modeling
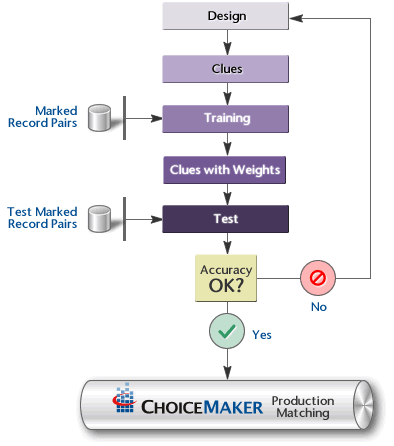
Design, Train, Test
This iterative process continues until the model under development achieves a satisfactory accuracy (compared to human markings) on the test pairs. Once the accuracy is adequate, the model is ready to be deployed in a production application or to a production server.
Bootstrapping
What constitutes good pairs for training and testing? First and foremost, the pairs used for training and testing should be distinct. A pair that is used for training should not be used for testing. Also, a pair that is used for training or for testing should be used only once. Second, pairs that are used for either training or testing should be relatively ambiguous. The accuracy of a ChoiceMaker model compared to human intuition is generally not improved by including a bunch of pairs that are obvious matches (in which all fields agree exactly) or obvious holds (in which all fields are missing or invalid) or obvious differs (in which all fields are completely different).
How does one find good pairs? There are several ChoiceMaker tools that will comb through a database of (single) records and pull out pairs of records with ambiguous ChoiceMaker probabilities. Typically, these tools use the same ChoiceMaker model that is under development to find pairs that score ambiguously under that model. Human data experts then review the new pairs, and mark the pairs as matches, holds and differs. Early in the development process, pairs that score ambiguously to the nascent model typically do not appear at all ambiguous to human reviewers, so when the model is trained against the newly marked pairs, the model weights move toward values that push pair probabilities toward less ambiguous scores. As the iterative process continues, human markings and ChoiceMaker probabilities begin to coalesce.
Content on this site is licensed under a Creative
Commons Attribution-Share Alike 3.0 United States
License.
Open Source ChoiceMaker Technology is available at SourceForge.net.

Open Source ChoiceMaker Technology is available at SourceForge.net.