Overview
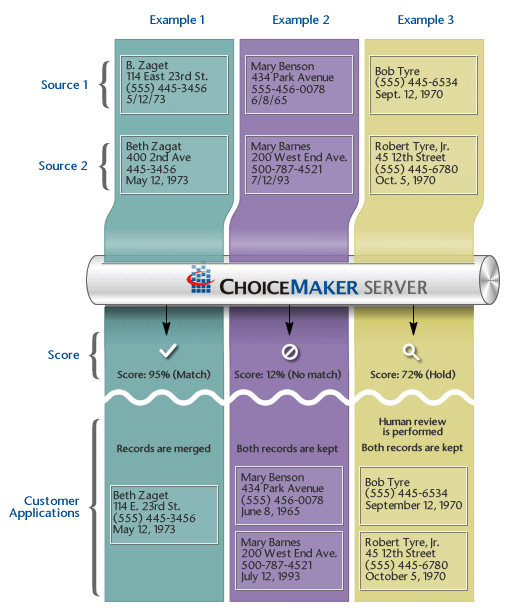
In Example 1, the information in the records is closely similar, although not identical. The degree of similarty is high enough that ChoiceMaker software assigns the records a match probability of 93 percent, and on that basis, some customer application merges the records to eliminate the duplication.
In Example 2, there is little similarity between the records, so ChoiceMaker assigns a low match probability of just 12 percent, and the records are kept as distinct entries in the database.
Finally, in Example 3, it is not clear whether the records represent the same person, particularly if there's a chance that some of the data might be erroneous or out-of-date. ChoiceMaker assigns an intermediate match probability to these pairs, so that the customer application can hold them aside for further human review.
Why
In the case of an immunization registry, it is important to avoid duplicate records for children so that each child receives a complete set of inoculations. In the case of a state-wide student registry, it is important to avoid duplicates so that the state can comply with the mandates of the federal No Child Left Behind Act.
How
Even when errors and incomplete or ambiguous data are present, human beings usually have a reliable intuition for whether two database records match each other. That's because human beings can consider information in context, and factor out unimportant differences or similarities between records. In the case of personnel records, humans recognize that "Jim" and "James" are nicknames; that "Keanu Reeves" and "Reaves, Keenu" might be the same person with first and last name swapped and slightly misspelled; and that two persons named "Maria Garcia" with a common birthdate of "1/1/2001" might not be a particularly strong match to each other, because the names are not uncommon and the birthdates look like approximations.
ChoiceMaker software works by mimicking human intuition. It does this in a straightforward way. The software compares two records at a time. For each field in the pair of records, the software applies simple true or false tests, called clues, to check whether the field values point toward a match. For example, in the case of first names, the following tests might be applied:
Match clues:
- Do the values of the two records match each other exactly?
- Do the values match each other phonetically?
- Do the values match each other if a few letters are transposed?
- Are the values nicknames for each other?
- Are the values completely different?
- Is one (or both) of the values missing, invalid or a
placeholder?
After all the clues are evaluated for a pair of records, ChoiceMaker combines the results into an overall probability score. It does this by assigning each clue a numerical weight that indicates its relative significance in the probability calculation.
Machine learning
- Do the pairs match each other (a match decision)?
- Are different from each other (a differ decision)?
- Is there not enough information to decide (a hold decision)?
Generality
Content on this site is licensed under a Creative
Commons Attribution-Share Alike 3.0 United States
License.
Open Source ChoiceMaker Technology is available at SourceForge.net.

Open Source ChoiceMaker Technology is available at SourceForge.net.